Prometheus : アラートの設定 (Email)2021/06/03 |
|
Prometheus のアラートの設定です。
Prometheus のアラートは、類似のアラートをグループ化してまとめ、一回で通知することが可能なため、不要な通知を極力省くといったことができます。
アラートの受け取り方法は、Slack, HipChat, WeChat 等々、多くの手段が提供されていますが、当例では Email での通知の設定をします。
アラート設定の詳細は公式サイトを参照ください。
⇒ https://prometheus.io/docs/alerting/configuration/ |
|
| [1] |
メールでの通知をする場合は、使用可能な SMTP サーバーが必要となります。
当例ではローカルホストで SMTP サーバーが稼働していることを前提に設定します。 |
| [2] | Prometheus サーバーが稼働するホストで、アラートの機能を提供する Alertmanager をインストールします。 |
|
[root@dlp ~]# dnf -y install alertmanager |
| [3] | 例として、Email で通知する場合の Alertmanager の設定です。 |
|
[root@dlp ~]#
mv /etc/prometheus/alertmanager.yml /etc/prometheus/alertmanager.yml.org [root@dlp ~]# vi /etc/prometheus/alertmanager.yml # 新規作成 global: # 使用する SMTP サーバー smtp_smarthost: 'localhost:25' # TLS 要/不要 smtp_require_tls: false # 通知メールの送信者アドレス smtp_from: 'Alertmanager <root@dlp.srv.world>' # SMTP Auth を設定している場合はアカウント名とパスワード # smtp_auth_username: 'alertmanager' # smtp_auth_password: 'password' route: # 通知先の Receiver 名 receiver: 'email-notice' # アラートをグループ化する条件 group_by: ['alertname', 'Service', 'Stage', 'Role'] # グループ化されたアラートを初回通知するまでの待ち時間 # 待ち時間の間に発生した同様のアラートはグループ化される group_wait: 30s # 通知済みのグループアラートに新しいアラートが追加された場合の次回通知までの待ち時間 group_interval: 5m # 通知済みの同内容のアラートを再送信する間隔 repeat_interval: 4h receivers: # 任意の [Receiver] 名 - name: 'email-notice' email_configs: # 通知先アドレス - to: "root@localhost" # 新規作成 # 例として [node-exporter] の [Up/Down] を監視
groups:
- name: Instances
rules:
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: critical
annotations:
description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.'
summary: 'Instance {{ $labels.instance }} down'
[root@dlp ~]#
vi /etc/prometheus/prometheus.yml
alerting:
alertmanagers:
- static_configs:
- targets:
# 12行目 : コメント解除して [(Alertmanager 稼働ホスト):(ポート)] に変更
- 'localhost:9093'
# 18行目 : 作成したアラートルールを追記
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
- "alert_rules.yml"
[root@dlp ~]# systemctl restart prometheus alertmanager [root@dlp ~]# systemctl enable alertmanager |
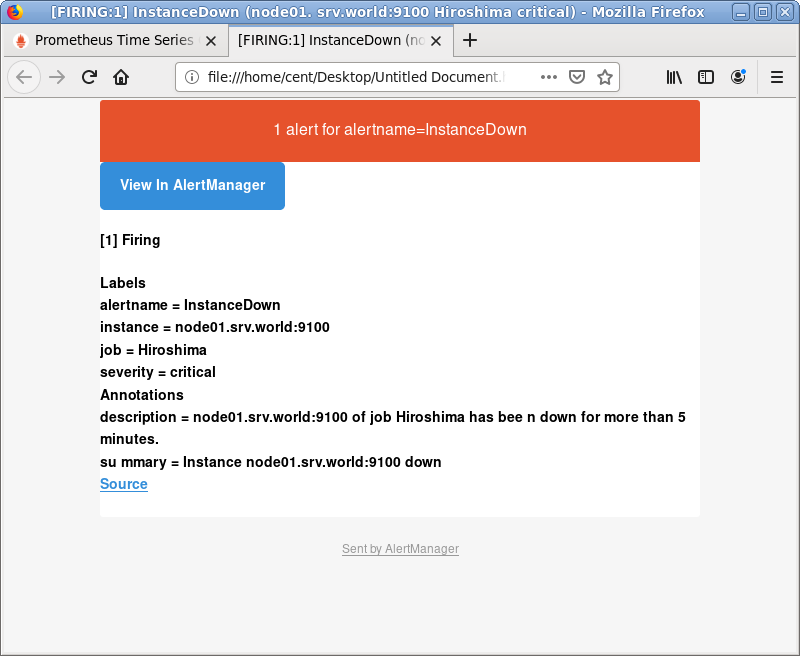
| [4] | [node-exporter] がダウンすると以下のようなメールが送信されます。(本文は HTML 形式) |
|
[root@dlp ~]# mail Message 19: From root@dlp.srv.world Wed Jun 2 20:18:38 2021 Return-Path: <root@dlp.srv.world> X-Original-To: root@localhost Delivered-To: root@localhost From: Alertmanager <root@dlp.srv.world> Subject: [FIRING:1] InstanceDown (node01.srv.world:9100 Hiroshima critical) To: root@localhost Date: Wed, 02 Jun 2021 20:18:37 -0500 Content-Type: multipart/alternative; boundary=bde99c641c75ec2265b8f69f8a2c06868 58896abaa6872b1b4a9d480447a Status: R Part 1: Content-Type: text/html; charset=UTF-8 ..... ..... |
|
関連コンテンツ