SpeedyCGIを使う2011/05/07 |
|
SpeedyCGI を使って Perlスクリプトの実行を高速化します。
mod_perlと異なるのは、
SpeedyCGI のプロセスは Apacheプロセスとは分離して動作するところです。
|
|
| [1] | SpeedyCGI インストール |
|
[root@www ‾]# yum --enablerepo=epel -y install perl-CGI-SpeedyCGI # EPELからインストール |
| [2] |
使い方(コードの記述方法)です。
例えば、以下のような単に0に1を足して表示するスクリプトがあったとします。
記述自体は特に変える必要はなく、頭のパスを「#!/usr/bin/speedy」にかえてやればよいだけです。 ただし、mod_perlのRegistryモードと同じく、 変数の扱い方等、コードの書き方に注意が必要です。 |
#!/usr/local/bin/perl
use strict;
use warnings;
print "Content-type: text/html\n\n";
print "<html>\n<body>\n";
print "<div style=\"width:100%; font-size:40px; font-weight:bold; text-align:center;\">";
my $a = 0;
&number();
print "</div>\n</body>\n</html>";
sub number {
$a++;
print "number \$a = $a";
}
|
| 通常の Perlスクリプトとして実行すると以下のような応答が返ります。当然ですが何度リロードしても同じ結果です。 |
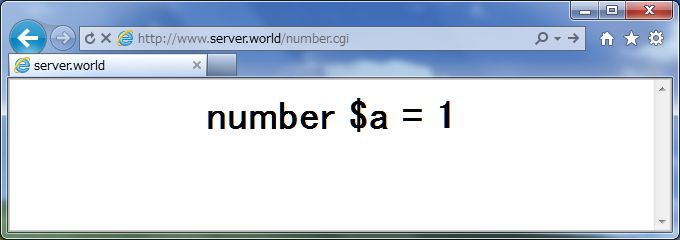
|
| これを頭のパスをかえて SpeedyCGI対応で動作させるとリロードする毎に値がどんどん増えていきます。 |
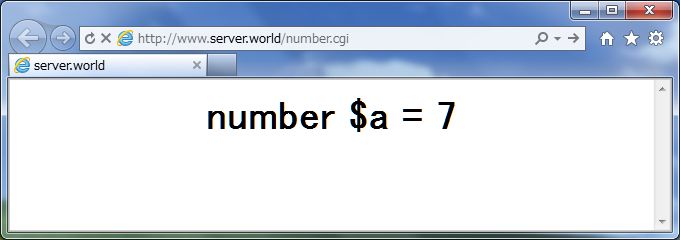
|
| このように、変数の値もメモリに保持するため、コードの書き方によっては意図した動作をしなくなります。 今回の例では、SpeedyCGI対応にする場合、以下のようにすることで本来の動作となります。 |
#!/usr/bin/speedy use strict; use warnings; print "Content-type: text/html\n\n"; print "<html>\n<body>\n"; print "<div style=\"width:100%; font-size:40px; font-weight:bold; text-align:center;\">"; my $a = 0;
&number(
$a );
print "</div>\n</body>\n</html>";
sub number {
my($a) = @_; $a++; print "number \$a = $a"; } |
|
SpeedyCGI の主なオプションです。「#!/usr/bin/speedy --」に続けてオプションを指定します。
(1) -t秒数例 ⇒ #!/usr/bin/speedy -- -t300 -M1 指定の秒数後、何も新しいリクエストを受け取らなければ常駐perlインタープリタを終了
(2) -M数字(デフォルトは3600秒) 指定数だけバックエンドのプロセスを制限
(3) -Bバッファ数(デフォルトは0。すなわち制限なし) perlバックエンドからデータを受け取るバッファ数を指定
(4) -bバッファ数(バイト単位で指定。デフォルトは131072バイト) perlバックエンドにデータを送るバッファ数を指定
(5) -r回数(バイト単位で指定。デフォルトは131072バイト) 指定回数実行したらバックエンドプロセスを再起動 (デフォルトは500回) |
関連コンテンツ