llama-cpp-python : インストール2024/02/19 |
|
Meta の Llama (Large Language Model Meta AI) モデルのインターフェースである [llama.cpp] の Python バインディング [llama-cpp-python] をインストールします。 |
|
| [1] | |
| [2] | その他必要なパッケージをインストールしておきます。 |
|
root@dlp:~# apt -y install python3-pip python3-dev python3-venv gcc g++ make jq curl |
| [3] | 任意の一般ユーザーでログインして、[llama-cpp-python] インストール用の Python 仮想環境を準備します。 |
|
debian@dlp:~$ python3 -m venv --system-site-packages ~/llama debian@dlp:~$ source ~/llama/bin/activate (llama) debian@dlp:~$ |
| [4] | [llama-cpp-python] をインストールします。 |
|
(llama) debian@dlp:~$ pip3 install llama-cpp-python[server] Collecting llama-cpp-python[server] Downloading llama_cpp_python-0.2.44.tar.gz (36.6 MB) Installing build dependencies ... done Getting requirements to build wheel ... done Installing backend dependencies ... done Preparing metadata (pyproject.toml) ... done ..... ..... Successfully installed annotated-types-0.6.0 anyio-4.2.0 diskcache-5.6.3 exceptiongroup-1.2.0 fastapi-0.109.2 h11-0.14.0 llama-cpp-python-0.2.44 numpy-1.26.4 pydantic-2.6.1 pydantic-core-2.16.2 pydantic-settings-2.1.0 python-dotenv-1.0.1 sniffio-1.3.0 sse-starlette-2.0.0 starlette-0.36.3 starlette-context-0.3.6 typing-extensions-4.9.0 uvicorn-0.27.1 |
| [5] |
[llama.cpp] で使用可能な GGUF 形式のモデルをダウンロードして、[llama-cpp-python] を起動します。 ⇒ https://huggingface.co/TheBloke/Llama-2-13B-chat-GGUF/tree/main ⇒ https://huggingface.co/TheBloke/Llama-2-70B-Chat-GGUF/tree/main |
|
(llama) debian@dlp:~$
(llama) debian@dlp:~$ wget https://huggingface.co/TheBloke/Llama-2-13B-chat-GGUF/resolve/main/llama-2-13b-chat.Q4_K_M.gguf python3 -m llama_cpp.server --model ./llama-2-13b-chat.Q4_K_M.gguf --host 0.0.0.0 --port 8000 &
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = LLaMA v2
llama_model_loader: - kv 2: llama.context_length u32 = 4096
llama_model_loader: - kv 3: llama.embedding_length u32 = 5120
llama_model_loader: - kv 4: llama.block_count u32 = 40
llama_model_loader: - kv 5: llama.feed_forward_length u32 = 13824
llama_model_loader: - kv 6: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 7: llama.attention.head_count u32 = 40
llama_model_loader: - kv 8: llama.attention.head_count_kv u32 = 40
llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 10: general.file_type u32 = 15
llama_model_loader: - kv 11: tokenizer.ggml.model str = llama
llama_model_loader: - kv 12: tokenizer.ggml.tokens arr[str,32000] = ["<unk>", "<s>", "</s>", "<0x00>", "<...
llama_model_loader: - kv 13: tokenizer.ggml.scores arr[f32,32000] = [0.000000, 0.000000, 0.000000, 0.0000...
llama_model_loader: - kv 14: tokenizer.ggml.token_type arr[i32,32000] = [2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, ...
llama_model_loader: - kv 15: tokenizer.ggml.bos_token_id u32 = 1
llama_model_loader: - kv 16: tokenizer.ggml.eos_token_id u32 = 2
llama_model_loader: - kv 17: tokenizer.ggml.unknown_token_id u32 = 0
llama_model_loader: - kv 18: general.quantization_version u32 = 2
llama_model_loader: - type f32: 81 tensors
llama_model_loader: - type q4_K: 241 tensors
llama_model_loader: - type q6_K: 41 tensors
llm_load_vocab: special tokens definition check successful ( 259/32000 ).
llm_load_print_meta: format = GGUF V2
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 32000
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 4096
llm_load_print_meta: n_embd = 5120
llm_load_print_meta: n_head = 40
llm_load_print_meta: n_head_kv = 40
llm_load_print_meta: n_layer = 40
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 5120
llm_load_print_meta: n_embd_v_gqa = 5120
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: n_ff = 13824
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_yarn_orig_ctx = 4096
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: model type = 13B
llm_load_print_meta: model ftype = Q4_K - Medium
llm_load_print_meta: model params = 13.02 B
llm_load_print_meta: model size = 7.33 GiB (4.83 BPW)
llm_load_print_meta: general.name = LLaMA v2
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
llm_load_tensors: ggml ctx size = 0.14 MiB
llm_load_tensors: CPU buffer size = 7500.85 MiB
..........................warning: failed to mlock 58060800-byte buffer (after previously locking 2057080832 bytes): Cannot allocate memory
Try increasing RLIMIT_MEMLOCK ('ulimit -l' as root).
..........................................................................
llama_new_context_with_model: n_ctx = 2048
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: CPU KV buffer size = 1600.00 MiB
llama_new_context_with_model: KV self size = 1600.00 MiB, K (f16): 800.00 MiB, V (f16): 800.00 MiB
llama_new_context_with_model: CPU input buffer size = 15.01 MiB
llama_new_context_with_model: CPU compute buffer size = 200.00 MiB
llama_new_context_with_model: graph splits (measure): 1
AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 |
Model metadata: {'tokenizer.ggml.unknown_token_id': '0', 'tokenizer.ggml.eos_token_id': '2', 'general.architecture': 'llama', 'llama.context_length': '4096', 'general.name': 'LLaMA v2', 'llama.embedding_length': '5120', 'llama.feed_forward_length': '13824', 'llama.attention.layer_norm_rms_epsilon': '0.000010', 'llama.rope.dimension_count': '128', 'llama.attention.head_count': '40', 'tokenizer.ggml.bos_token_id': '1', 'llama.block_count': '40', 'llama.attention.head_count_kv': '40', 'general.quantization_version': '2', 'tokenizer.ggml.model': 'llama', 'general.file_type': '15'}
INFO: Started server process [2518]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
|
| [6] | ローカルネットワーク内の任意のコンピューターから [http://(サーバーのホスト名 または IP アドレス):8000/docs] にアクセスすると、ドキュメントを参照することができます。 |
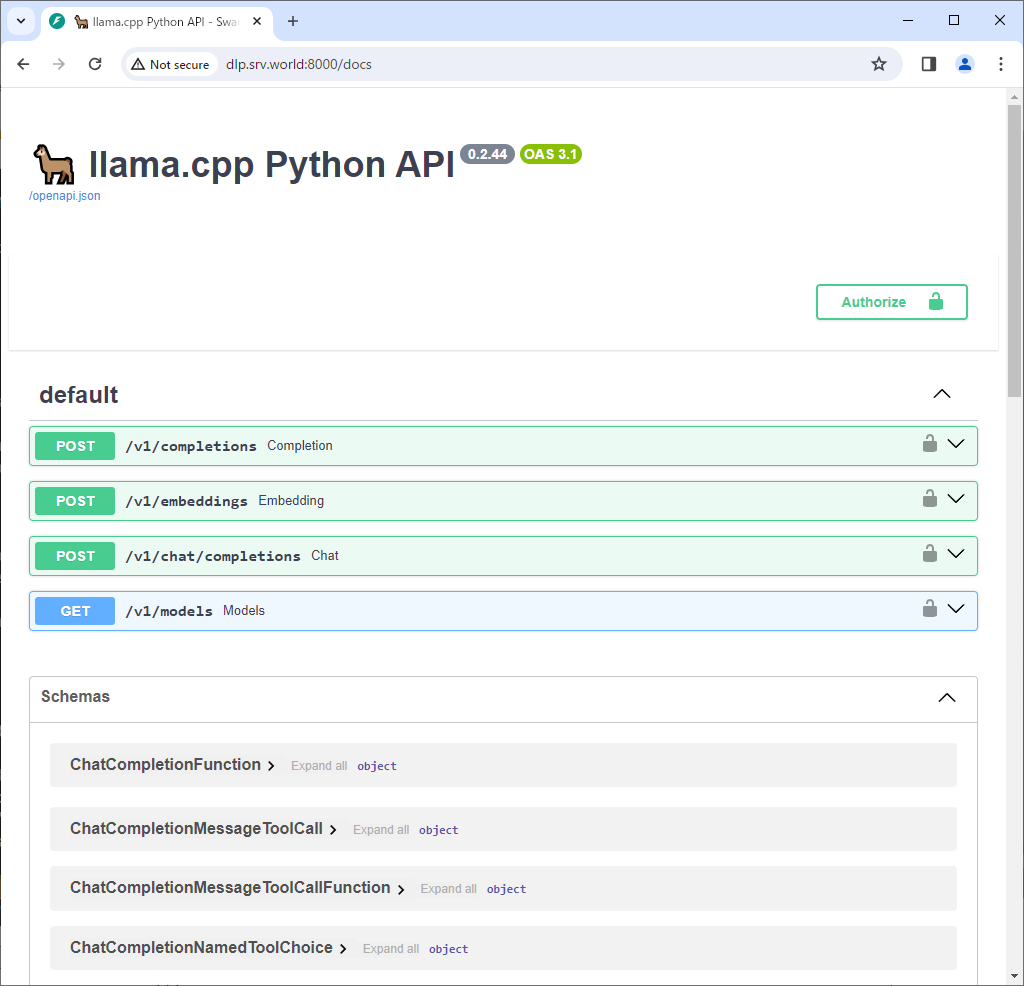
|
| [7] | 簡単な質問を投入して動作確認します。 質問の内容や使用しているモデルによって、応答時間や応答内容はまちまちですが、応答時間については CPU のみで実行しているため、ある程度はかかります。 ちなみに、当例では、8 vCPU + 16G メモリ のマシンで実行しています。 |
|
# Llama について教えて (llama) debian@dlp:~$ curl -s -XPOST -H 'Content-Type: application/json' localhost:8000/v1/chat/completions \ -d '{"messages": [{"role": "user", "content": "Tell me about Llama."}]}' | jq
llama_print_timings: load time = 4138.86 ms
llama_print_timings: sample time = 237.35 ms / 410 runs ( 0.58 ms per token, 1727.40 tokens per second)
llama_print_timings: prompt eval time = 1794.76 ms / 8 tokens ( 224.35 ms per token, 4.46 tokens per second)
llama_print_timings: eval time = 162149.98 ms / 409 runs ( 396.45 ms per token, 2.52 tokens per second)
llama_print_timings: total time = 165410.80 ms / 417 tokens
INFO: 127.0.0.1:37558 - "POST /v1/chat/completions HTTP/1.1" 200 OK
{
"id": "chatcmpl-25048ce2-0ee2-489e-b2b9-fdc62973230d",
"object": "chat.completion",
"created": 1708326389,
"model": "./llama-2-13b-chat.Q4_K_M.gguf",
"choices": [
{
"index": 0,
"message": {
"content": " Compared to other text-to-image generation models, LLaMA is a more advanced model that uses deep learning to generate images from text descriptions. The technology can be used to generate realistic images of objects, animals, and scenes, and can even be used to create interactive 3D animations.\n\nHowever, it's important to note that the quality of the generated images will depend on the quality and detail of the input text. For example, if the input text is vague or lacks detail, the generated image may be less accurate or less detailed. Additionally, the model may not always be able to capture the exact likeness of the subject, especially if it is a complex or abstract concept.\n\nDespite these limitations, LLaMA has the potential to revolutionize the way we create and interact with digital content. With its ability to generate high-quality images and animations from text descriptions, it could be used in a variety of applications, such as:\n\n1. Graphic design: LLaMA could be used to create high-quality graphics and designs for a variety of industries, such as advertising, fashion, and entertainment.\n2. Animation: The technology could be used to create interactive 3D animations for movies, TV shows, and video games.\n3. Virtual reality: LLaMA could be used to create realistic virtual reality experiences for industries such as healthcare, education, and tourism.\n4. E-commerce: The technology could be used to create high-quality product images and animations for e-commerce websites and apps.\n5. Social media: LLaMA could be used to create engaging and interactive content for social media platforms, such as Facebook and Instagram.\n\nOverall, LLaMA has the potential to revolutionize the way we create and interact with digital content, and could have a significant impact on a variety of industries and applications.",
"role": "assistant"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 19,
"completion_tokens": 409,
"total_tokens": 428
}
}
# 次回オリンピックは、いつ、どこで開催? (llama) debian@dlp:~$ curl -s -XPOST -H 'Content-Type: application/json' localhost:8000/v1/chat/completions \ -d '{"messages": [{"role": "user", "content": "When and where will the next Olympics be held?"}]}' | jq | sed -e 's/\\n/\n/g'
llama_print_timings: load time = 4138.86 ms
llama_print_timings: sample time = 101.28 ms / 186 runs ( 0.54 ms per token, 1836.40 tokens per second)
llama_print_timings: prompt eval time = 1966.03 ms / 9 tokens ( 218.45 ms per token, 4.58 tokens per second)
llama_print_timings: eval time = 72678.28 ms / 185 runs ( 392.86 ms per token, 2.55 tokens per second)
llama_print_timings: total time = 75284.42 ms / 194 tokens
INFO: 127.0.0.1:45930 - "POST /v1/chat/completions HTTP/1.1" 200 OK
{
"id": "chatcmpl-c2445ab9-ecc6-4faa-ae6f-5cdb54885fb0",
"object": "chat.completion",
"created": 1708326803,
"model": "./llama-2-13b-chat.Q4_K_M.gguf",
"choices": [
{
"index": 0,
"message": {
"content": " The Summer Olympic Games are scheduled to take place in Tokyo, Japan, from July 24 to August 9, 2020. The Winter Olympic Games are scheduled to take place in Beijing, China, from February 4 to February 20, 2022.
Here is a list of upcoming Olympic Games:
* Summer Olympic Games:
\t+ Tokyo, Japan (2020)
\t+ Paris, France (2024)
\t+ Los Angeles, USA (2028)
* Winter Olympic Games:
\t+ Beijing, China (2022)
\t+ Milan/Cortina d'Ampezzo, Italy (2026)
Note: The list above is subject to change based on the International Olympic Committee's (IOC) decision.",
"role": "assistant"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 21,
"completion_tokens": 185,
"total_tokens": 206
}
}
|
| [8] |
日本語モデルもいくつか提供されています。 ⇒ https://huggingface.co/mmnga/ELYZA-japanese-Llama-2-13b-fast-instruct-gguf |
|
(llama) debian@dlp:~$
curl -LO https://huggingface.co/mmnga/ELYZA-japanese-Llama-2-13b-fast-instruct-gguf/resolve/main/ELYZA-japanese-Llama-2-13b-fast-instruct-q5_0.gguf
(llama) debian@dlp:~$
(llama) debian@dlp:~$ python3 -m llama_cpp.server --model ./ELYZA-japanese-Llama-2-13b-fast-instruct-q5_0.gguf --host 0.0.0.0 --port 8000 &
curl -s -XPOST -H 'Content-Type: application/json' localhost:8000/v1/chat/completions \ -d '{"messages": [{"role": "user", "content": "次回のオリンピックはどこで開催?"}]}' | jq
llama_print_timings: load time = 3266.01 ms
llama_print_timings: sample time = 5.81 ms / 21 runs ( 0.28 ms per token, 3614.46 tokens per second)
llama_print_timings: prompt eval time = 2643.76 ms / 12 tokens ( 220.31 ms per token, 4.54 tokens per second)
llama_print_timings: eval time = 7751.69 ms / 20 runs ( 387.58 ms per token, 2.58 tokens per second)
llama_print_timings: total time = 10477.29 ms / 32 tokens
INFO: 127.0.0.1:33286 - "POST /v1/chat/completions HTTP/1.1" 200 OK
{
"id": "chatcmpl-c5472ea6-3ed2-438e-9b15-247a322468b3",
"object": "chat.completion",
"created": 1708067530,
"model": "./ELYZA-japanese-Llama-2-13b-fast-instruct-q5_0.gguf",
"choices": [
{
"index": 0,
"message": {
"content": " 2024年夏季オリンピックの開催地は、フランス・パリに決定しました。",
"role": "assistant"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 18,
"completion_tokens": 20,
"total_tokens": 38
}
}
|
関連コンテンツ