Stable Video Diffusion : Install2024/02/23 |
|
Install [Stable Video Diffusion] that is the Image-to-Video model of deep learning. |
|
| [1] | |
| [2] | Install other required packages. |
|
root@dlp:~# apt -y install python3-pip python3-venv git ffmpeg
|
| [3] | Login as a common user install [Stable Video Diffusion]. |
|
# create a python virtual environment ubuntu@dlp:~$ python3 -m venv --system-site-packages ~/video ubuntu@dlp:~$ source ~/video/bin/activate
git clone https://github.com/Stability-AI/generative-models.git (video) ubuntu@dlp:~$ cd generative-models (video) ubuntu@dlp:~/generative-models$ pip3 install -r ./requirements/pt2.txt ..... ..... Successfully installed PyWavelets-1.5.0 aiofiles-23.2.1 aiohttp-3.9.3 aiosignal-1.3.1 altair-5.2.0 annotated-types-0.6.0 antlr4-python3-runtime-4.9.3 anyio-4.3.0 appdirs-1.4.4 async-timeout-4.0.3 black-23.7.0 braceexpand-0.1.7 cachetools-5.3.2 chardet-5.1.0 charset-normalizer-3.3.2 clip-1.0 cmake-3.28.3 contourpy-1.2.0 cycler-0.12.1 docker-pycreds-0.4.0 einops-0.7.0 exceptiongroup-1.2.0 fairscale-0.4.13 fastapi-0.109.2 ffmpy-0.3.2 filelock-3.13.1 fire-0.5.0 fonttools-4.49.0 frozenlist-1.4.1 fsspec-2024.2.0 ftfy-6.1.3 gitdb-4.0.11 gitpython-3.1.42 gradio-4.19.2 gradio-client-0.10.1 h11-0.14.0 httpcore-1.0.4 httpx-0.27.0 huggingface-hub-0.20.3 importlib-resources-6.1.1 invisible-watermark-0.2.0 jedi-0.19.1 kiwisolver-1.4.5 kornia-0.6.9 lightning-utilities-0.10.1 lit-17.0.6 markdown-it-py-3.0.0 matplotlib-3.8.3 mdurl-0.1.2 mpmath-1.3.0 multidict-6.0.5 mypy-extensions-1.0.0 natsort-8.4.0 networkx-3.2.1 ninja-1.11.1.1 numpy-1.26.4 nvidia-cublas-cu11-11.10.3.66 nvidia-cuda-cupti-cu11-11.7.101 nvidia-cuda-nvrtc-cu11-11.7.99 nvidia-cuda-runtime-cu11-11.7.99 nvidia-cudnn-cu11-8.5.0.96 nvidia-cufft-cu11-10.9.0.58 nvidia-curand-cu11-10.2.10.91 nvidia-cusolver-cu11-11.4.0.1 nvidia-cusparse-cu11-11.7.4.91 nvidia-nccl-cu11-2.14.3 nvidia-nvtx-cu11-11.7.91 omegaconf-2.3.0 open-clip-torch-2.24.0 opencv-python-4.6.0.66 orjson-3.9.14 packaging-23.2 pandas-2.2.0 parso-0.8.3 pathspec-0.12.1 pillow-10.2.0 platformdirs-4.2.0 protobuf-3.20.3 psutil-5.9.8 pudb-2024.1 pyarrow-15.0.0 pydantic-2.6.1 pydantic-core-2.16.2 pydeck-0.8.1b0 pydub-0.25.1 pygments-2.17.2 python-dateutil-2.8.2 python-multipart-0.0.9 pytorch-lightning-2.0.1 pyyaml-6.0.1 regex-2023.12.25 requests-2.31.0 rich-13.7.0 ruff-0.2.2 safetensors-0.4.2 scipy-1.12.0 semantic-version-2.10.0 sentencepiece-0.2.0 sentry-sdk-1.40.5 setproctitle-1.3.3 shellingham-1.5.4 smmap-5.0.1 sniffio-1.3.0 starlette-0.36.3 streamlit-1.31.1 streamlit-keyup-0.2.0 sympy-1.12 tenacity-8.2.3 tensorboardx-2.6 termcolor-2.4.0 timm-0.9.16 tokenizers-0.12.1 toml-0.10.2 tomli-2.0.1 tomlkit-0.12.0 toolz-0.12.1 torch-2.0.1 torchaudio-2.0.2 torchdata-0.6.1 torchmetrics-1.3.1 torchvision-0.15.2 tornado-6.4 tqdm-4.66.2 transformers-4.19.1 triton-2.0.0 typer-0.9.0 typing-extensions-4.9.0 tzdata-2024.1 tzlocal-5.2 urllib3-1.26.18 urwid-2.6.4 urwid-readline-0.13 uvicorn-0.27.1 validators-0.22.0 wandb-0.16.3 watchdog-4.0.0 wcwidth-0.2.13 webdataset-0.2.86 websockets-11.0.3 wheel-0.42.0 xformers-0.0.22 yarl-1.9.4(video) ubuntu@dlp:~/generative-models$ pip3 install ./ ..... ..... Successfully built sgm Installing collected packages: sgm Successfully installed sgm-0.1.0
(video) ubuntu@dlp:~/generative-models$
vi ./scripts/demo/streamlit_helpers.py # line 61 : change to True if the installed graphics board has low memory capacity # * value of [False] did not work on an RTX 3060 with 12G RAM lowvram_mode = True
# download a model, models are here # https://huggingface.co/stabilityai/stable-video-diffusion-img2vid/tree/main # https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt/tree/main (video) ubuntu@dlp:~/generative-models$ mkdir ./checkpoints (video) ubuntu@dlp:~/generative-models$ curl -L https://huggingface.co/stabilityai/stable-video-diffusion-img2vid/resolve/main/svd.safetensors?download=true -o ./checkpoints/svd.safetensors # if app wont work even if with lowvram mode, set env to reduce the value like follows (video) ubuntu@dlp:~/generative-models$ export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:64
# run the server (video) ubuntu@dlp:~/generative-models$ cp -p ./scripts/demo/video_sampling.py ./ (video) ubuntu@dlp:~/generative-models$ streamlit run video_sampling.py --server.address=0.0.0.0 Collecting usage statistics. To deactivate, set browser.gatherUsageStats to False. You can now view your Streamlit app in your browser. URL: http://0.0.0.0:8501 |
| [4] | Access to the port 8501 that was shown on your command line, then you can use [Stable Video Diffusion]. Check a box [Load Model]. |
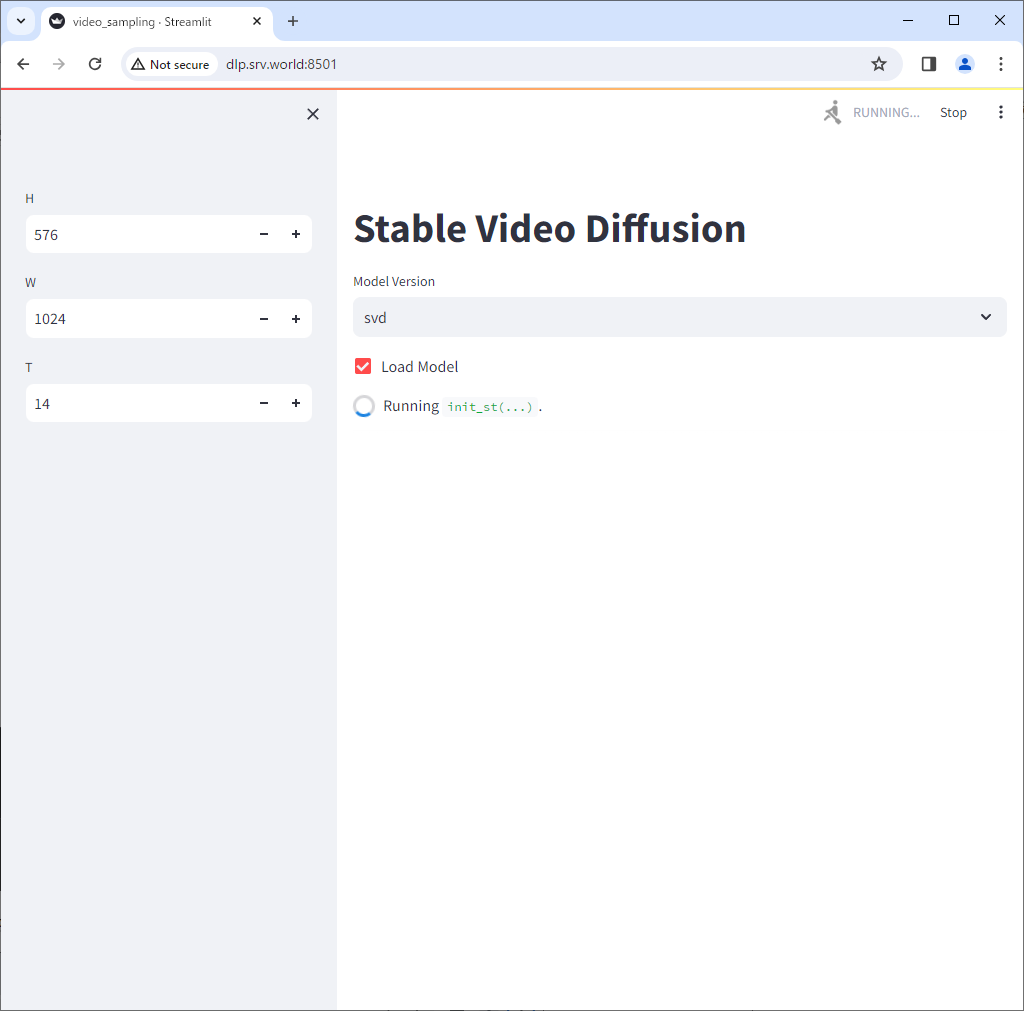
|
| [5] | The initial loading will take quite a while. After finishing loading, following screen is displayed. Ignore the error below. Next, click [Browse files] to select an image you like to convert to video. |
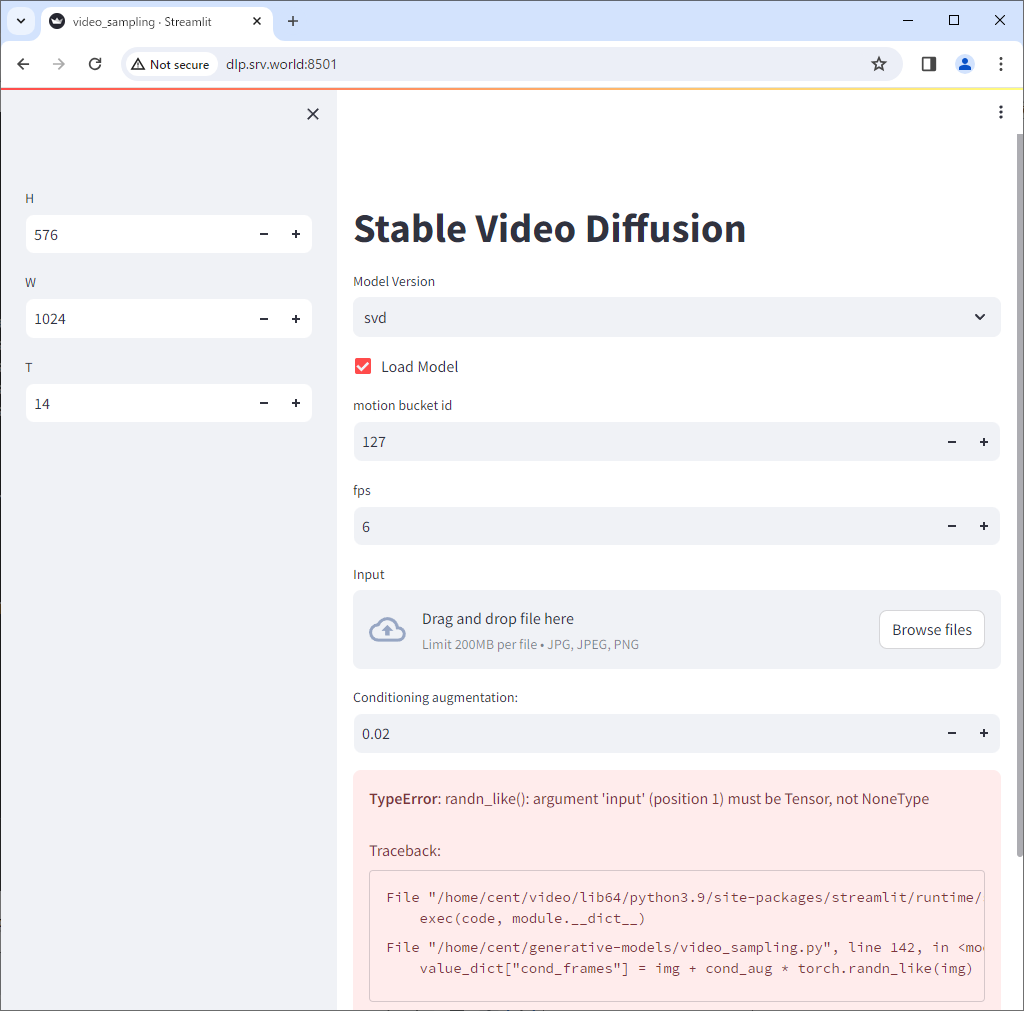
|
| [6] | After loading your image, it will be put on the screen. By the way, the image of pig below was generated using Stable Diffusion. |

|
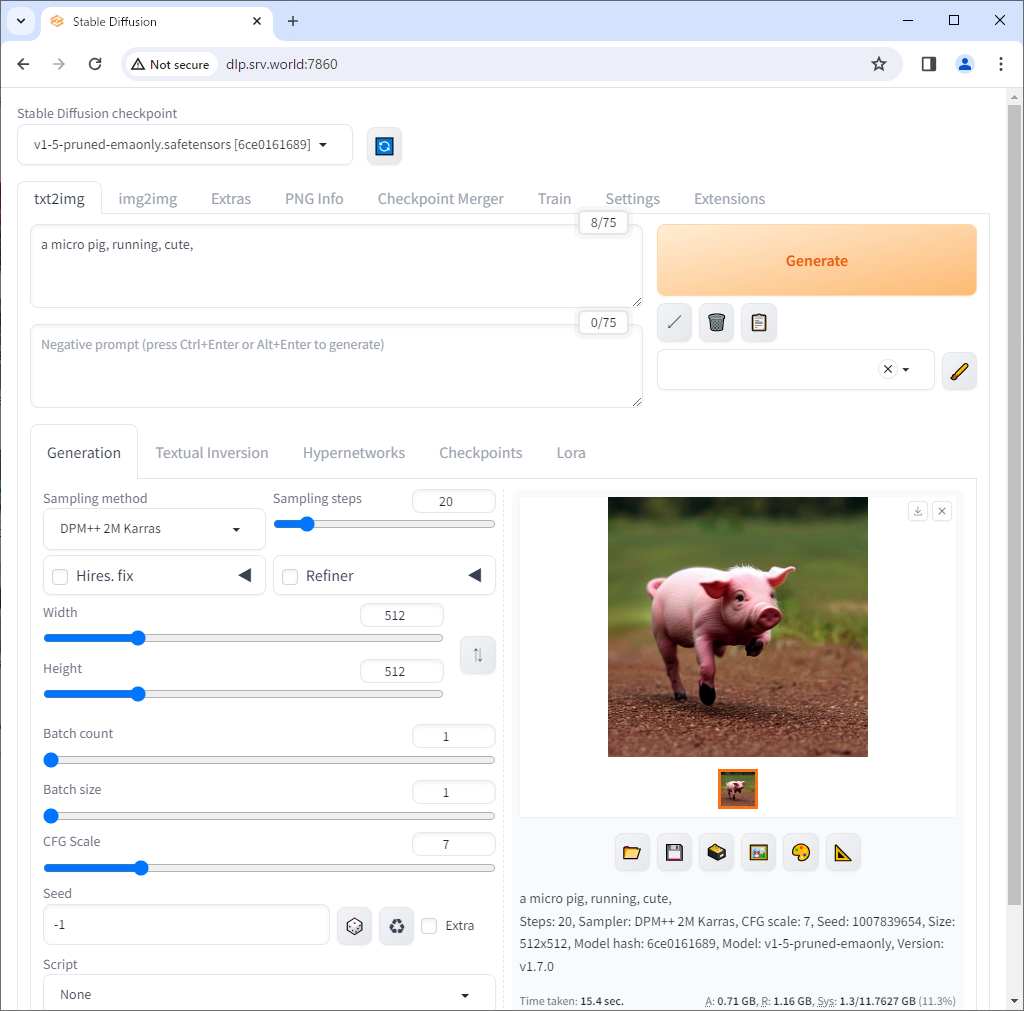
|
| [7] |
Scroll down the page and adjust each value.
the value [H] and [W] ⇒ change to the size of the image |

|
| [8] | After successfully generated a video, it will be displayed on the screen. With the RTX 3060 12G RAM, the best I could do was generate a 2-second video with [svd]. |
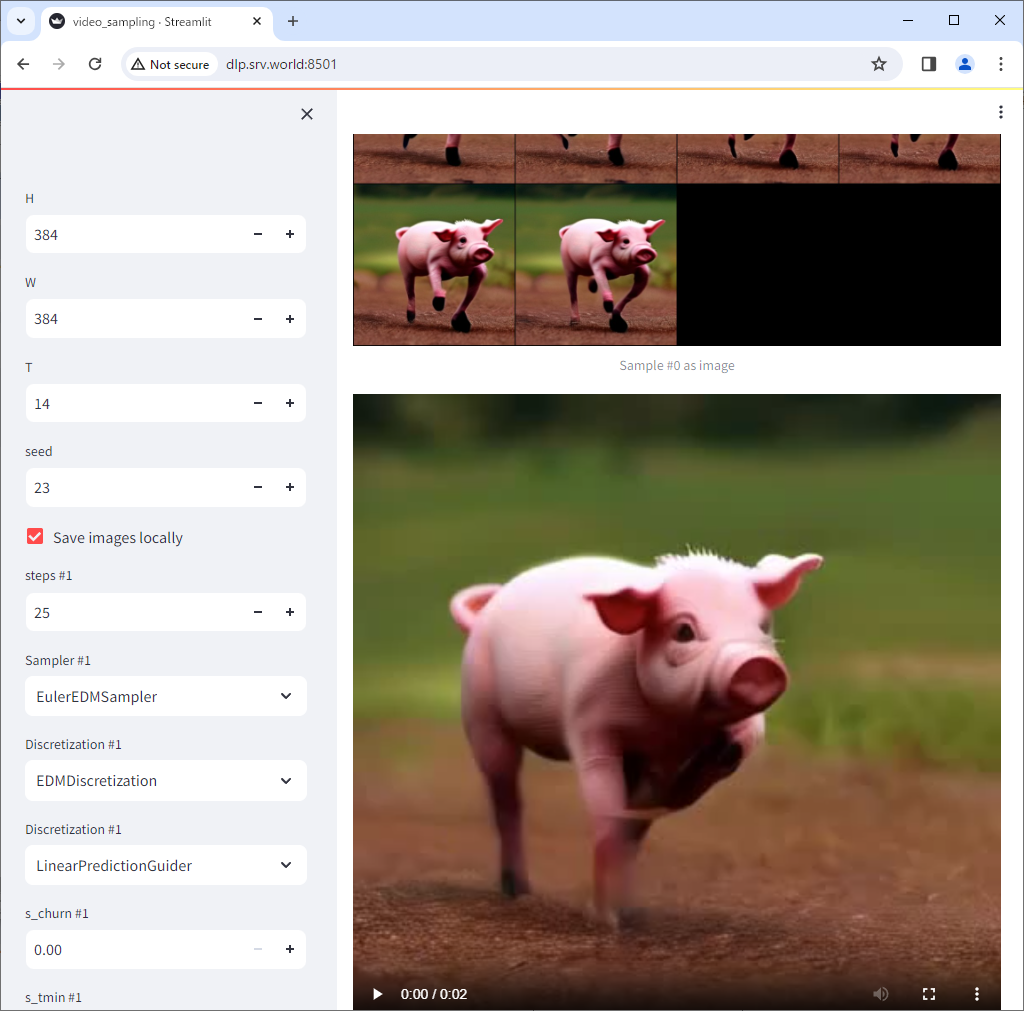
|
Matched Content